Sep 25, 2022
Apache Hadoop MapReduce 是一套被业界广泛运用在计算机集群上并行处理大型数据的开源系统。
我们特别邀请了资深软件工程师猴哥给我们介绍Apache Hadoop MapReduce 的原理和代码。
以下是本次活动笔记.
MapReduce
概述
为什么要有GFS/HDFS这种分布式文件系统?随着近年来各公司部门的数据量呈明显递增趋势,我们有迫切的需求来存储这些数据。但不仅仅是为了像网盘一样存储大文件,而是为了接下来由大量数据参与的计算。
什么是最有效的处理大量数据的手段?拆,分治。MapReduce是一种在分布式文件系统上运行的分治处理数据的计算方式。Map的意思是“映射”,他是以每一条记录为输入,若干条记录为输出进行的计算;Reduce的意思是“归并”、“归约”… 他是以一组记录为单位做为输入的计算。
计算程序和被计算的文件都位于分布式集群中,对于他们如何协调和分配?尽量使得计算向数据移动。
什么是MapReduce计算中优化的要点?尽量减少I/O,计算向数据移动 + 算法
常识复习:HDFS中有哪些角色?(注:根据Hadoop-2.6.5)
大概流程
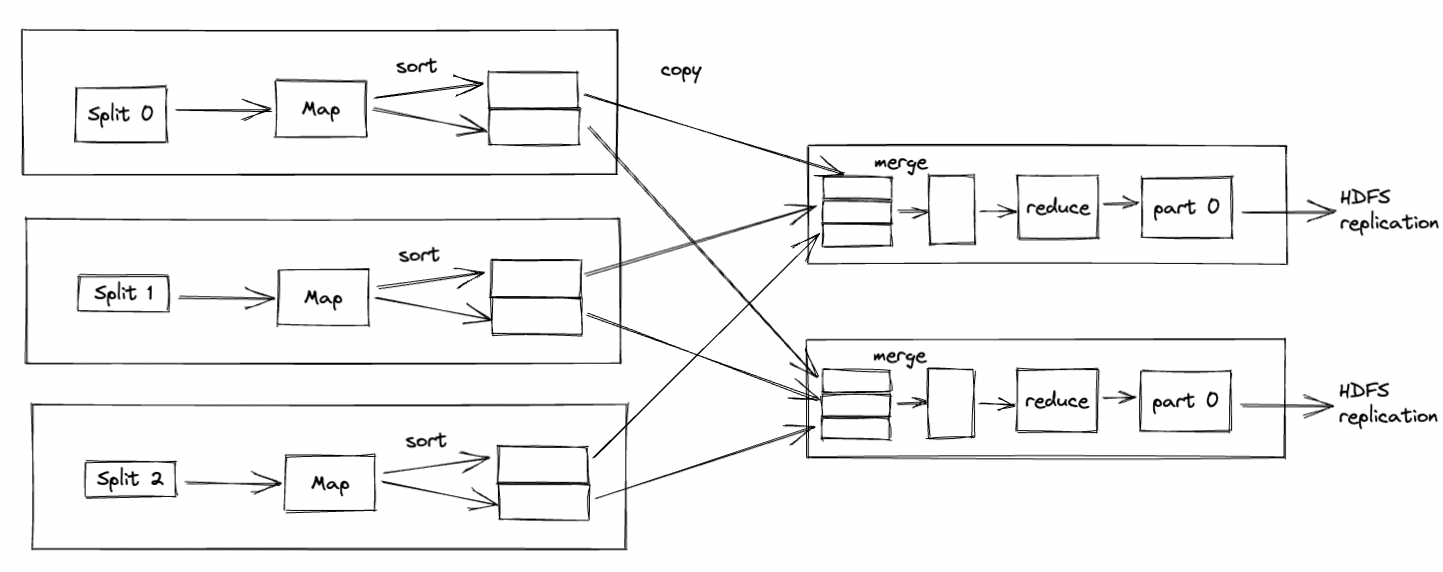
map reduce high level
- 客户端计算切片、上传Jar文件和配置到HDFS。
- MapReduce程序被调起,上传上来的Jar文件被拉取到各个计算节点(调度需要yarn,略)
- MapReduce集群以反射的方式,加载各个Mapper、Reducer类
- 在最合适的节点启动各个MapTask(分治),以预先定义的“一条条”的数据(怎样算是一条数据?)为输入,进行计算
- MapTask的数量取决于split的个数
- 各个MapTask结束后,生成了键值对形式的中间数据,且每一个键值对都经历了一次分区计算,计算了其将会被哪个Reducer处理(分区,Partition == Reducer)。中间数据被存储在了Map节点的本地磁盘。Partitioner (Hash)
- 数据被拉取到其所属的各个Reducer分别进行计算(分治)。ReduceTask的个数可以手动配置。默认为1.
- Reducer生成计算结果文件,写在HDFS中
客户端代码:
public class MyWordCount {
public static void main(String[] args) throws Exception{
// load the xml files in resources
Configuration conf = new Configuration(true);
GenericOptionsParser parser = new GenericOptionsParser(conf, args); // accept the cmd params
String otherArgs[] = parser.getRemainingArgs(); // parse the params
// To run the progrma on Mac or Windows as well
conf.set("mapreduce.app-submission.cross-platform", "true");
conf.set("mapreduce.framework.name", "yarn");
Job job = Job.getInstance(conf);
// Upload this jar file
//job.setJar("/Users/shuzheng/IdeaProjects/hadoop-hdfs/target/hadoop-hdfs-1.0-SNAPSHOT.jar");
// Main class
job.setJarByClass(MyWordCount.class);
job.setJobName("myJob");
Path infile = new Path(otherArgs[0]);
TextInputFormat.addInputPath(job, infile);
Path outfile = new Path(otherArgs[1]);
if (outfile.getFileSystem(conf).exists(outfile)) {
outfile.getFileSystem(conf).delete(outfile, true);
}
TextOutputFormat.setOutputPath(job, outfile);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class); // Reflect
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(MyReducer.class);
job.setNumReduceTasks(2); // Set number of reduce tasks, default is 1
job.waitForCompletion(true);
}
}
public class MyMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable ONE = new IntWritable(1);
private final static Text WORD = new Text();
// Word count中,key是当前这一行文本在文件中的偏移量,value是其内容
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// StringTokenizer will split the string on " \t\n\r\f"
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
WORD.set(itr.nextToken());
context.write(WORD, ONE); // MapTask line 1156:keySerializer.serialize(key);
}
}
}
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
// Word Count: key是单词,value是1或者combine之后的出现次数(并非最终结果)
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException { // List?
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
详细流程和底层原理
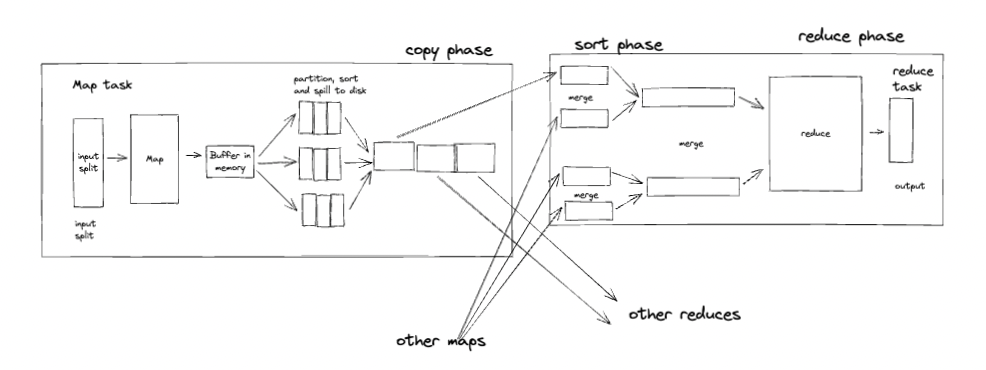
map reduce low level
现在只是聚焦于某一个MapTask和ReduceTask。k-v-partition
- 客户端在对于split的计算中,其默认大小是block size,但是也可以被设置为大于或者小于block size(默认128MB)。为什么?这是由于计算的不同属性:I/O密集型、CPU密集型。
- 计算程序被以反射的方式加载,以便后面运行其中的计算方法
- map方法对于每一条(默认情况下,是以一行文本为一条记录)记录输出的key-value-Partition,会根据不同的key计算出其对应的分区(Reducer),并把Partition assign给他,且并不会立刻落盘,而是先写到一个环形缓冲区中. 计算分区非常重要,是承上启下的一步计算,关系到下面的分治(Hash)计算 ,Spark中的 join(cogroup算子)、Hive/Spark SQL中的group by等操作都有赖于Partitioner
- 环形缓冲区的大小默认100MB,80%(MapOutputBuffer.init)被使用了之后就触发spill,由另一个线程写磁盘,为了不阻塞主计算线程。落盘之前,根据各个key做排序和combine(optional, 相当于map端的“小reduce”)
- Combine的逻辑跟reduce是一样的。
- 环形缓冲区经过多次spill,可以生成若干个小文件(100MB以内),将他们合并成一个大文件。这里I/O成本比较高。
- Map计算结束以后,各个Reducer通过http协议拉取属于自己的数据(Shuffle)。这里注意:相同的key为一组,组不可分,这些相同key的k-v必须去往同一个Partition(Reducer的拉取由Yarn来调度)。
- Reducer对拉取过来的文件一边归并一边以一组数据(相同的key)为单位交给用户自定义的reduce()方法进行迭代,而无需先合并成一个完整的中间文件。这里用到了两个设计模式:模版方法和迭代器。
最后的结果也是以HDFS中的文件的形式给出,自然也会有多个副本,保证了数据的可靠性
举例
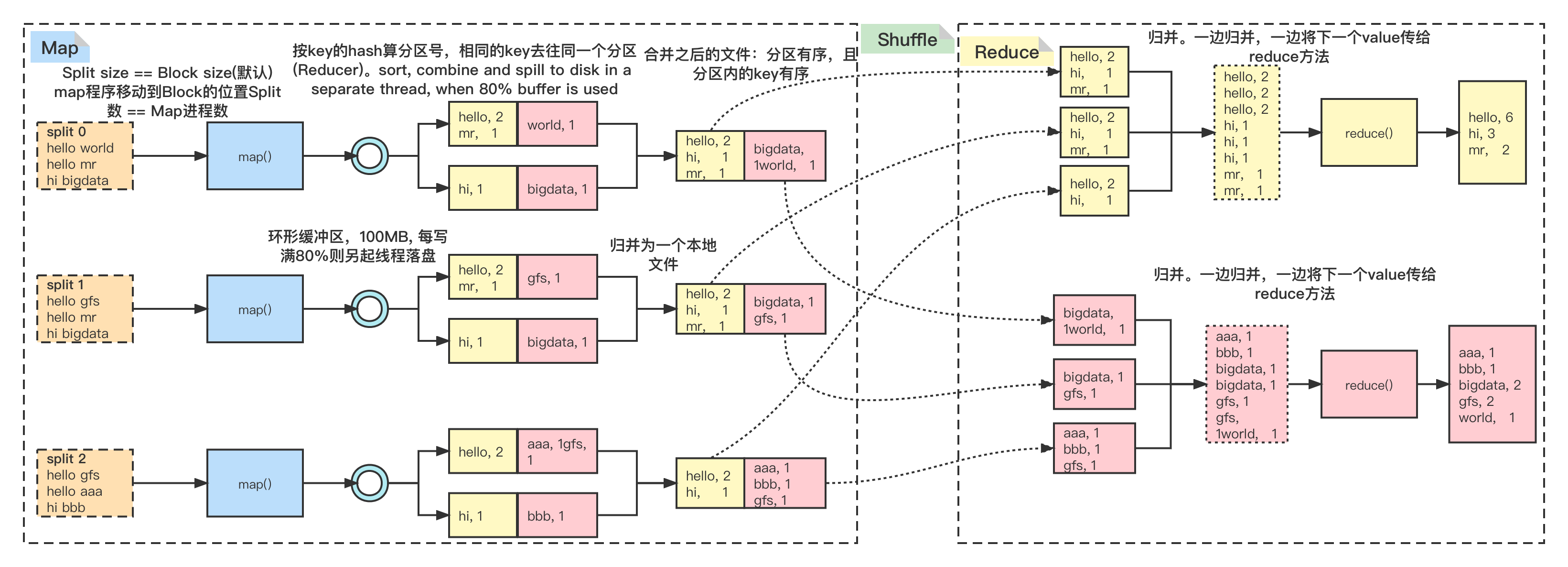
实际运行结果:
(base) [root@hadoop-04 ~]# hdfs dfs -text /data/wc/output2/part-r-00000
aaa 1
hi 3
mr 2
(base) [root@hadoop-04 ~]# hdfs dfs -text /data/wc/output2/part-r-00001
bbb 1
bigdata 2
gfs 2
hello 6
world 1
图中数据臆测了各个key的Hash值,所以改变了结果在最终生成文件中的分布,但并不影响其正确性和相对顺序。
问题:对于词频的频率如何统计?
总结:
block : split
1:1
N:1
1:N
split : map
1:1
map : reduce
N:1 default
N:N (相同的key必须到同一个reduce所处理)
1:1
~~1:N~~ **(Not allowed)
key:partion N:1**
*相关源码(hadoop-2.6.5,只是某些要点):
- 客户端定义split计算:Job.waitForCompletion … JobSubmitter.writeNewSplits() … FileInputFormat.getSplits。 如果不特别设置,则默认split大小就是block size
- MapTask的调用:MapTask.run,其中每一行文本调用了一次map方法(默认行为,TextInputFormat、LineRecordReader)
- map方法中context.write会被用户调用,在其中会: 计算分区号(分区计算很重要,Hive,Spark SQL group by)、排序、combine、序列化(不覆盖相同的key)、spill
- *Shuffle部分:Shuffle → Fetcher.run → copyFromHost → Fetcher.copyMapOutput → mapOutput.shuffle
- Fetcher.copyFromHost: 拉模型,Reducer去Mapper拉取数据。Reducer端负责发起Shuffle,以http的方式,见Fetcher.connection成员
- ReduceTask.run: 封装迭代器 传给context,进而传给用户定义的reduce方法。 MergeQueue才是真·迭代器,其next方法实现有序迭代已排序的大文件
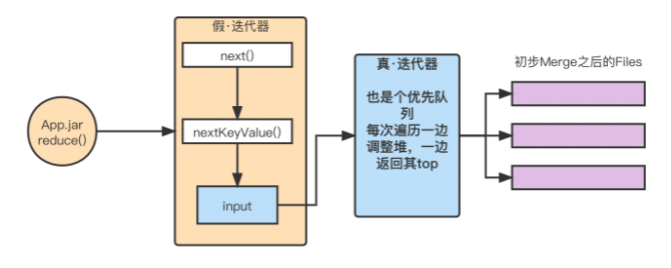
- 总结:算法、数据结构、设计模式、线程模型、I/O模型是基础
延伸
MapReduce的缺点是什么?Spark是如何解决的?
- Spark缓存了中间数据,这些数据可以被存在内存、磁盘和分布式文件系统(RDD iterator,cache和checkpoint),方便重复使用和失败重试
- 多个算子搭配,相当于多个MapReduce可以顺序执行,而不用每个MR程序依次单独启动
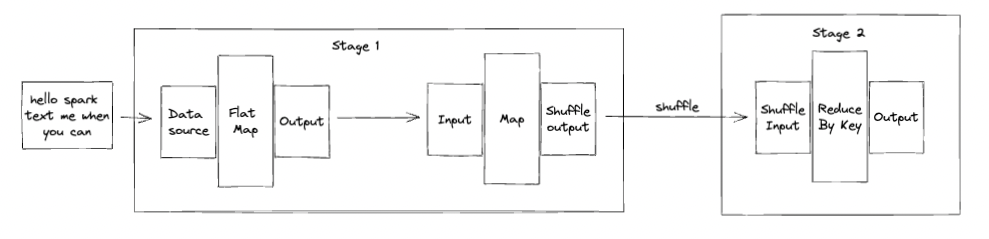
spark word count
- 针对于读取效率,Spark有的算子(sortByKey)会进行数据抽样,计算数据集算出取数据的步进,减少IO。比MapReduce优化了
- 通过MR程序可以看出,(除了配置信息)用户需要上传的就是map()和reduce()两个方法(函数),Spark/Scala的函数式编程正好对应用程序的代码量做了优化,使其更加简洁
- Spark通过构建DAG和划分Stage,达到了更细粒度的任务调度,一旦有任务失败,则仅仅重试该Stage,而不用像MapReduce一样,中间某一步失败,要想重试就必须得start over
- MapReduce是“冷程序”,只有提交之后才会进行资源分配并启动执行,且执行完了就结束进程;Spark是“热服务”,资源一开始就抢占好了,等spark任务提交上来就直接开始执行,且执行完成之后,Spark进程还在还会利用它已经抢占的这些资源,接受其他的任务
- 内存优化。1. 更细粒度的划分内存:on/off heap memory,堆外内存有效节省了内存的使用量,且不用麻烦GC(但是读写需要序列化、反序列化)。2. 执行内存和存储内存之间可以弹性伸缩、挤压(BlockManager、钨丝计划)
- 更加频繁且优雅地使用了迭代器模式。用迭代器串联起了多个算子的类似递归的调用, e.g.: word count: forech,println(reduceByKey(map(flatMap())))
- IFile.Reader.nextRawKey/Value()每次只读一个K or V。Spark有的算子(sortByKey)会进行抽样,计算数据集算出取数据的步进,减少IO。比MapReduce优化了
在其他的维度,有没有什么解决办法?多个Map Reduce任务如何平滑地依次执行?Map Reduce集群是不是功能太不单纯了?业务上是不是也有可以改进的地方?
map reduce shuffle combine → 对MR集群拆分微服务(Spark之外的另一个拓展维度)
Join us on WeChat

Ming Dao School uses 1-1 coaching and group events to help high-tech professionals grow their careers and handle career transitions.
If you like to join our upcoming mock system design interview events or other coaching programs, please contact us on LinkedIn.